
Paper link | Note link | Code link | EMNLP 2023
這項研究對多個大型視覺語言模型(LVLMs)進行了評估實驗,以檢查它們對物體幻覺的易感性。
大型視覺語言模型(LVLMs)可能會遇到物體幻覺的問題,即生成的描述包含與目標圖像不匹配的物體。
這項研究介紹了一種名為 POPE 的基於投票的查詢方法,以改進物體幻覺的評估。
大型視覺語言模型(LVLMs)使用來自視覺語言預訓練模型(VLPMs)的視覺編碼器,並將語言編碼器替換為大型語言模型(LLMs),以處理圖像數據並按照人類指示執行各種任務。
然而,LVLMs 仍然會遇到幻覺問題,即生成的內容可能包含圖像中不存在的物體。
下圖顯示了 LVLMs 中物體幻覺的情況。

粗體 物體表示真實物體,而 紅色 物體表示幻覺物品。左側案例使用傳統的基於指令的評估方法,右側案例使用三種不同變體的 POPE 方法。
下圖顯示了 MSCOCO 數據集中常見或共現物體的幻覺頻率。

這個指標廣泛用於評估圖像標註任務中的物體幻覺問題。
現有方法通常使用兩個變體:
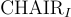 用於評估物體實例層級的幻覺。
用於評估物體實例層級的幻覺。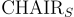 用於評估句子層級的幻覺。
用於評估句子層級的幻覺。它們的公式如下:
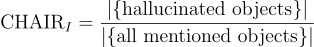
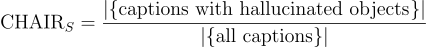
CHAIR 的缺點包括對指令設計和標註長度等因素的敏感性,這些因素可能會影響評估結果。
這項研究引入了基於輪詢的物體探測評估(POPE),這是一種簡單而有效的評估 LVLMs 幻覺的方法。

在給定輸入圖像的情況下,POPE 首先使用人類標註或自動分割工具(如 SEEM)提取真實物體。
然後,POPE 在隨機、流行或對抗設置下進行負樣本採樣,這些設置包括不存在的物體。
最後,POPE 將這些物體製成問題模板來輪詢 LVLMs。
與 CHAIR 不同,POPE 在提示形式上更穩定,並且可以輕鬆擴展到未標註的數據集。
其探測結果也與模型的標註高度一致。
這項研究使用 POPE 評估了所有的 LVLMs,基於 MSCOCO 的驗證集。
下表顯示了在 MSCOCO 驗證集上,三種 POPE 評估設置下的 LVLMs 結果。表中的“是”表示回答“是”的比例。每個區塊中的最佳結果以粗體顯示。

下表顯示了 LLaVA 使用不同提示模板的 POPE 和 CHAIR 評估結果。

下表顯示了基於 SEEM 的 POPE 結果,針對 MSCOCO 上的 LVLMs。F1 Score(Truth)結果是使用真實標註獲得的。每個區塊中的最佳結果以粗體顯示。


 iThome鐵人賽
iThome鐵人賽